
Olá, pessoal! Neste post, irei trazer uma pequena experiência usando a Tensorflow Object Detection API. Trata-se de uma aplicação em Python para detecção de objetos em tempo real, que utiliza esta API como backend. É necessário ter uma webcam no seu computador para executar o projeto.
A TensorFlow Object Detection API é uma estrutura de código aberto construída sobre o TensorFlow, que facilita a construção, treinamento e implantação de modelos de detecção de objetos.
Para esta aplicação, será utilizado um modelo pré-treinado oferecido pela API, o SSD MobileNet v1 (COCO), que possui velocidade rápida (30 ms) e um índice de precisão de 21%.
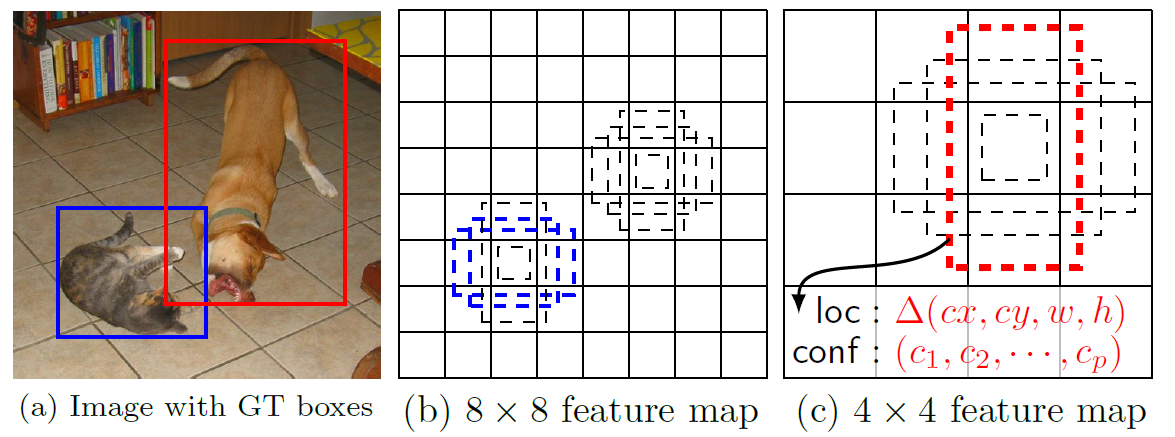
SSD – Single Shot MultiBox Detector
O Single Shot MultiBox Detector é um método para detecção objetos em imagens que usa uma única rede neural profunda. Ele difere de outros detectores de single shot devido ao uso de múltiplas camadas que proporcionam uma precisão mais fina em objetos com diferentes escalas (cada camada mais profunda verá objetos maiores). Aqui você encontra o paper original: https://arxiv.org/pdf/1512.02325.pdf.
O SSD normalmente começa com um modelo pré-treinado que é convertido em uma rede neural totalmente convolutiva. Em seguida, são anexadas algumas camadas de convolução extras, que ajudarão a detectar objetos maiores na imagem.
O termo “Multibox” se refere à etapa anterior ao Single Shot Detector, dentro da arquitetura do SSD. Ele divide a imagem em diversos segmentos, e desenha caixas delimitadoras em torno de cada um desses segmentos. Feito isso, o algoritmo verifica onde existe um objeto a ser detectado dentro dessas caixas (durante o processo de construção do modelo, nós informamos quais são as possíveis classes a serem detectadas).
Entendendo o código da aplicação
A aplicação irá iniciar a webcam e então iniciar a captura das imagens em vídeo. Cada frame do vídeo é processado como uma imagem, que recebe algumas tarefas de pré-processamento. Uma vez que a imagem tenha sido processada, ela é entregue ao modelo de aprendizagem de máquina fornecido pela API do TensorFlow, que então classifica a imagem e mostra o score, que é o percentual de certeza sobre a classificação.
Você pode baixar/clonar o código da aplicação clicando aqui. Abaixo, a implementação do object_detection_app.py com alguns comentários.
# object_detection_app.py
# Imports
import os
import math
import random
import numpy as np
import tensorflow as tf
import cv2
slim = tf.contrib.slim
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import sys
sys.path.append('../')
from nets import ssd_vgg_300, ssd_common, np_methods
from preprocessing import ssd_vgg_preprocessing
from app import visualization
# Sessão TensorFlow: aumenta a memória quando necessário.
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(log_device_placement=False, gpu_options=gpu_options)
isess = tf.InteractiveSession(config=config)
# Placeholders de Input
net_shape = (300, 300)
data_format = 'NHWC'
img_input = tf.placeholder(tf.uint8, shape=(None, None, 3))
# Pré-processamento: resize para. shape do SSD
image_pre, labels_pre, bboxes_pre, bbox_img = ssd_vgg_preprocessing.preprocess_for_eval(
img_input, None, None, net_shape, data_format, resize=ssd_vgg_preprocessing.Resize.WARP_RESIZE)
image_4d = tf.expand_dims(image_pre, 0)
# Define o modelo SSD
reuse = True if 'ssd_net' in locals() else None
ssd_net = ssd_vgg_300.SSDNet()
with slim.arg_scope(ssd_net.arg_scope(data_format=data_format)):
predictions, localisations, _, _ = ssd_net.net(image_4d, is_training=False, reuse=reuse)
# Restaura o modelo SSD
ckpt_filename = 'checkpoints/ssd_300_vgg.ckpt'
isess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(isess, ckpt_filename)
# SSD default anchor boxes
ssd_anchors = ssd_net.anchors(net_shape)
# Rotina de processamento das imagens
def process_image(img, select_threshold=0.5, nms_threshold=.45, net_shape=(300, 300)):
# Executa a rede SSD.
rimg, rpredictions, rlocalisations, rbbox_img = isess.run([image_4d, predictions, localisations, bbox_img],
feed_dict={img_input: img})
# Obtém classes e bboxes (bounding boxes) das saídas da rede
rclasses, rscores, rbboxes = np_methods.ssd_bboxes_select(
rpredictions, rlocalisations, ssd_anchors,
select_threshold=select_threshold, img_shape=net_shape, num_classes=21, decode=True)
rbboxes = np_methods.bboxes_clip(rbbox_img, rbboxes)
rclasses, rscores, rbboxes = np_methods.bboxes_sort(rclasses, rscores, rbboxes, top_k=400)
rclasses, rscores, rbboxes = np_methods.bboxes_nms(rclasses, rscores, rbboxes, nms_threshold=nms_threshold)
# Redimensiona bboxes para a forma original da imagem.
rbboxes = np_methods.bboxes_resize(rbbox_img, rbboxes)
return rclasses, rscores, rbboxes
# Testa nas imagens de teste
path = 'demo/'
image_names = sorted(os.listdir(path))
# Altera o valor de 1 a 7 para testar diferentes imagens
img = mpimg.imread(path + image_names[-4])
rclasses, rscores, rbboxes = process_image(img)
# Visualiza a imagem com os objetos detectados
visualization.plt_bboxes(img, rclasses, rscores, rbboxes)
Executando a aplicação
Os requisitos e instruções de uso estão disponíveis no arquivo README.md do projeto. Basicamente, será necessário ter o Anaconda instalado, com uma versão do Python igual ou superior a 3.6.5, além do OpenCV e TensorFlow.
Abaixo, um vídeo demonstrando um pouco da aplicação em funcionamento:
Pretendo trazer mais conteúdos relacionados a Visão Computacional, dessa vez mostrando como criar nossos próprios modelos. Essa é uma das áreas de IA que mais me chamam atenção.
Espero que tenham gostado! Até mais, pessoal! 😃